
Getting started with ODM
ODM stands for OpenDroneMap, an open-source photogrammetry software. OpenDroneMap project includes several modules which facilitate geospatial analysis in customized configurations of available computing power and for projects of different scales. The OpenDroneMap/ODM [GitHub] module is the analytical core of the software. Typically it is employed by the higher-level layers of other OpenDroneMap products that provide a graphical user interface or manage analysis configuration and task scheduling (learn more in the Introduction to OpenDroneMap section of the Geospatial Workbook.
The point is that you can directly use the ODM module on the command line in the terminal for drone imagery mapping. This tutorial will take you step-by-step through creating an efficient file structure and setting up a script to send the job to the SLURM queue on an HPC cluster, which will allow you to collect all the results of the photogrammetric analysis with OpenDroneMap.
The complete workflow includes photo alignment and generation of the dense point cloud (DPC), elevation models (DSMs & DTMs), textured 3D meshes, and orthomosaics (georeferenced & orthorectified). Note that in this approach there is NO support to create web tiles. So, the results can not be directly opened in the complementary WebODM graphical interface. But, the files can be still visualized in external software that supports the given format.
Run ODM in the command line
using Atlas cluster of the SCINet HPC
The OpenDroneMap/ODM module is available on the Atlas (and Ceres) clusters as a singularity container. The image of the software can be accessed on the path:
/reference/containers/opendronemap/2.8.3/opendronemap-2.8.3.sif
In your scripts, you can either set a variable to this path:
odm_exe=/reference/containers/opendronemap/2.8.3/opendronemap-2.8.3.sif
or you can create a softlink in your file structure and further use it:
ln -s /reference/containers/opendronemap/2.8.3/opendronemap-2.8.3.sif /<path-to-your-project-on-Atlas/odm.sif
In this tutorial, we will create a sample script that uses a variable to store the path to the original ODM image.
Create file structure
The ODM module for the command-line usage requires the specific file structure to work without issues. Specifically, it requires that input imagery be in the code/images subdirectories structure of the working directory for a given project.
To facilitate proper path management, I suggest creating the core of ordered file structure for all future projects. Let’s say it will be the ODM directory, serving as a working directory for all future ODM analyses. It should contain two main subdirectories: IMAGES and RESULTS. In the IMAGES directory, you will create a new folder with a unique name for each new project, where you will place photos in JPG format (e.g., ~/ODM/IMAGES/PROJECT-1). In the RESULTS directory, when submitting an ODM task into the SLURM queue, a subdirectory with ODM outputs will be automatically created for each project. And there, also automatically, an code/images subdirectories will be created with soft links to photos from the relative project.
|― run_odm.sh (SLURM job submission script)
|― IMAGES/
|― PROJECT-1/ (directory with images in JPG format and gcp_list.txt file with GCPs)
|― PROJECT-2/
|― RESULTS/ (parent directory for ODM analysis outputs)
|― PROJECT-1-tag/ (automatically created directory with ODM analysis outputs)
|― code/ (automatically created dir for analysis outputs; required!)
|― images/ (automatically created dir with soft links to JPG images)
This way, if you want to perform several analyses with different parameters on the same set of images, you will not need to have a hard copy for each repetition. Instead, you will use soft links to the original photos stored in the IMAGES directory. That will significantly save storage space and prevent you from accidentally deleting input imagery when resuming the analysis in the working directory.
To set up the file structure for ODM analysis follow the steps in the command line:
0. Open the terminal window on your local machine and login to the SCINet Atlas cluster (or any HPC infrastructure) using the ssh command and respective hostname:
ssh <user.name>@atlas-login.hpc.msstate.edu
Then, enter on the keyboard your 1) multi-factor authenticator number (6 digits), followed by 2) password in a separate prompt.
^ Note that when entering the identification code and password, the characters are not visible on the screen.
If you happen to forget the hostname for the Atlas cluster, you can save the login command to a text file in your home directory on your local machine:
$ echo "ssh user.name@atlas-login.hpc.msstate.edu" > ~/login_atlas
Then every time you want to log in, just call the name of this file with a dot and space preceding it:
$ . ~/login_atlas
You can also review the HPC clusters available on SCINet at https://scinet.usda.gov/guide/quickstart#hpc-clusters-on-scinet.
1. Once logged in to Atlas HPC, go into your group folder in the /project location
cd /project/<your_account_folder>/
# e.g., cd /project/90daydata
If you do not remember or do not know the name of your group directory in /project location, try the command:
$ ls /project
That will display all available group directories. You can search for suitable ones by name or you can quickly filter out only the ones you have access to:
$ ls /project/* 2> /dev/null
Note that you do NOT have access to all directories in the /project location. You also can NOT create the new directory there on your own. All users have access to /project/90daydata, but data is stored there only for 90 days and the folder is dedicated primarily to collaborative projects between groups. If you do NOT have access to your group's directory or need a directory for a new project request a new project allocation.
You can display the contents of any directory with access while being in any other location in the file system. To do this, you need to know the relative or absolute path to the target location.
The absolute path requires defining all intermediate directories starting from the root (shortcutted by a single /):
$ ls /project/90daydata
The relative path requires defining all intermediate directories relative to the current location. To indicate the parent directories use the ../ syntax for each higher level. To point to child directories you must name them directly. Remember, however, that pressing the tab key expands the available options, so you don't have to remember entire paths.
$ ls ../../inner_folder
The same principle applies to relocation in the file system using the cd command.
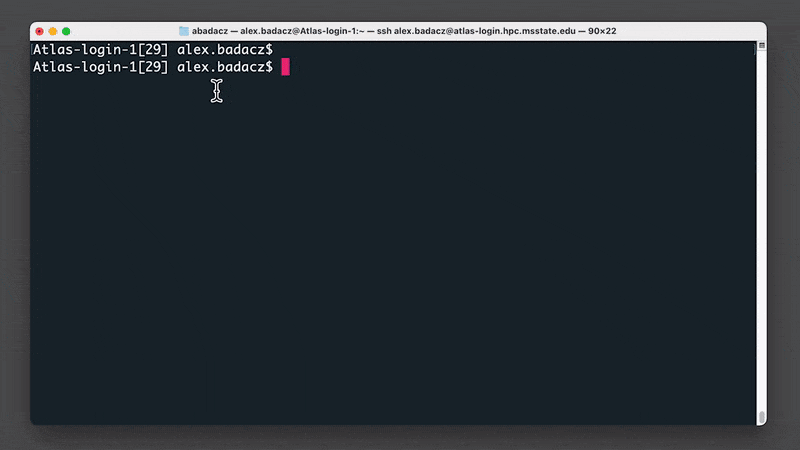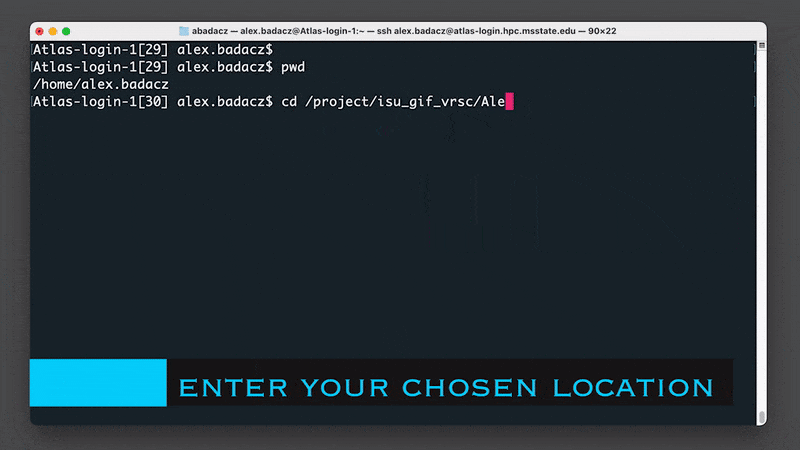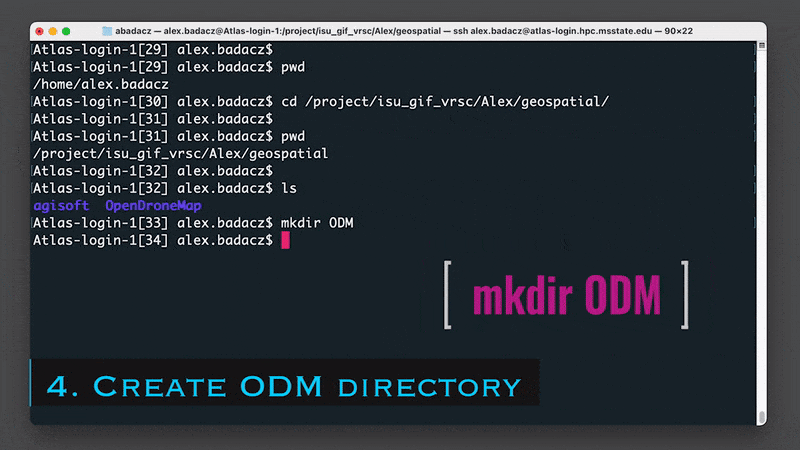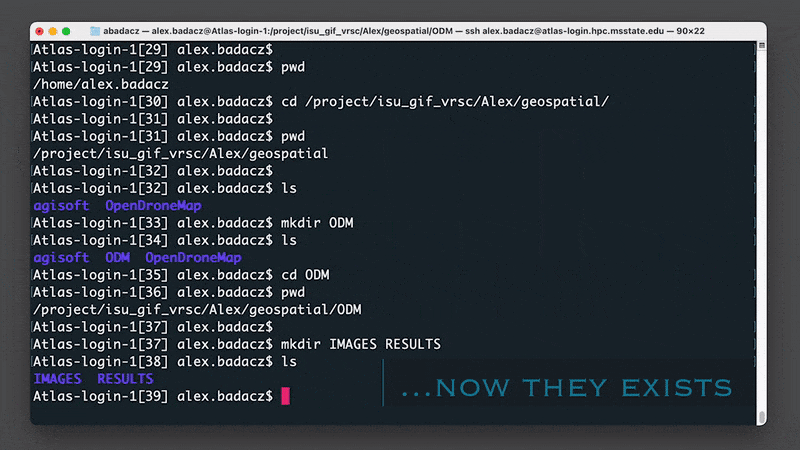
2. Create a working directory (mkdir) for all future ODM projects and get into it (cd):
mkdir ODM
cd ODM
3. Create a directory for input images (IMAGES) and ODM analysis outputs (RESULTS):
mkdir IMAGES RESULTS
Detect GCPs on the photos
Ground Control Points (GCPs) are clearly visible objects which can be easily identified in several images. Using the precise GPS position of these ground points is a good reference that improves significantly the accuracy of the project’s geolocation. Ground control points can be any steady structure existing in the mission area, otherwise can be set using targets placed on the ground.
ODM enables using the GCP data from a gcp_list.txt text file with the --gcp option.
--gcp gcp_list.txt
To create the gcp_list.txt file properly follow the instructions in the “Software for manual detection of GCPs” or “Automatic detection of ARUco targets” sections of the Geolocation data for the ODM workflow tutorial.
When the file is ready, place it in the project directory (within IMAGES dir) along with photos.
|― PROJECT-1/ (directory with images in JPG format and gcp_list.txt file with GCPs)
|― gcp_list.txt (GCPs file)
|― IMG_0001.jpg (photo 1)
|― IMG_0002.jpg (photo 2)
|― ...
Copy input imagery on Atlas
A. export from local machine
In case the input images are on your local machine, you can transfer them to HPC Atlas via the command line using the scp command with syntax:
scp <location on local machine> <user.name>@atlas-dtn.hpc.msstate.edu:<project location on Atlas cluster>.
The complete command should look like that:
scp /local/machine/JPGs/* alex.badacz@atlas-dtn.hpc.msstate.edu:/project/isu_gif/Alex/ODM/IMAGES/project-X
…and it has to be executed in the terminal window from the selected location in the file system on your local machine.
![]()
Note that you HAVE to use transfer nodes every time you want to move data to a cluster. Transfer nodes differ from login nodes by the hostname while your user.name remains the same.
For data transfer purposes, always use the transfer hostname: user.name@atlas-dtn.hpc.msstate.edu
You can also transfer data from your local machine to the Atlas cluster using the web-based Globus approach. Learn more by following the tutorial in the DataScience workbook: Copying Data using Globus.
B. import from other HPC
You can use the approach from section A to export data from any computing machine (including another HPC, e.g., Ceres) to an Atlas cluster. You need to be physically logged into that other machine and follow the procedure described in step A.
If you want to make a transfer from another machine while logged into Atlas then you will import the data. You can also do this using the scp command, but you NEED to know the hostname for that other external machine. The idea of syntax is simple:
scp source_location destination_location.
scp username@external-hostname:/path/JPGs/* /project/project_account/on/Atlas/ODM/IMAGES/project-X
Sometimes an external machine may require access from a specific port, in which case you must use the -P option, i.e.,
scp -P port_number source_host:location destination_location_on_atlas.
You can probably transfer data from other HPC infrastructure to the Atlas cluster using the web-based Globus approach. Learn more by following the tutorial in the DataScience workbook: Copying Data using Globus.
C. move locally on Atlas
To move data locally in the file system on a given machine (such as an Atlas cluster) use the cp command with the syntax:
cp source_location destination_location.
The complete command should look like that:
cp /project/90daydata/shared/project-X/JPGs/* /project/project_account/user/ODM/IMAGES/project-X
…and it has to be executed in the terminal window when logged into Atlas cluster.
Absolute paths work regardless of the current location in the file system. If you want to simplify the path syntax, first go to the source or destination location and replace them with ./* or ./ respectively. An asterisk (*) means that all files from the source location will be transferred.
transfer while in the source location: cp ./* /project/.../ODM/IMAGES/project-X
transfer while in the destination location: cp /project/90daydata/project-X/JPGs/* ./
Setup SLURM script
Make sure you are in your ODM working directory at the /project path:
pwd
It should return a string with your current location, something like /project/project_account/user/ODM. If the basename of your current directory is different from “ODM” use the cd command to get into it. When you get to the right location in the file system follow the next instructions.
Create an empty file for the SLURM script and open it with your favorite text editor:
touch run_odm_latest.sh
nano run_odm_latest.sh # nano, vim, mcedit are good text file editors
Copy-paste the template code provided below:
#!/bin/bash
# job standard output will go to the file slurm-%j.out (where %j is the job ID)
# DEFINE SLURM VARIABLES
#SBATCH --job-name="geo-odm" # custom SLURM job name visible in the queue
##SBATCH --partition=atlas # partition on Atlas: atlas, gpu, bigmem, service
#SBATCH --partition=short # partition on Ceres: short, medium, long, mem, longmem
#SBATCH --nodes=1 # number of nodes
#SBATCH --ntasks=48 # logical cores: 48 on atlas, 72 on short (Ceres)
#SBATCH --time=04:00:00 # walltime limit (HH:MM:SS)
#SBATCH --account=<project_account> # EDIT ACCOUNT, provide your SCINet project account
#SBATCH --mail-user=user.name@usda.gov # EDIT EMAIL, provide your email address
#SBATCH --mail-type=BEGIN # email notice of job started
#SBATCH --mail-type=END # email notice of job finished
#SBATCH --mail-type=FAIL # email notice of job failure
# LOAD MODULES, INSERT CODE, AND RUN YOUR PROGRAMS HERE
module load apptainer # load container dependency
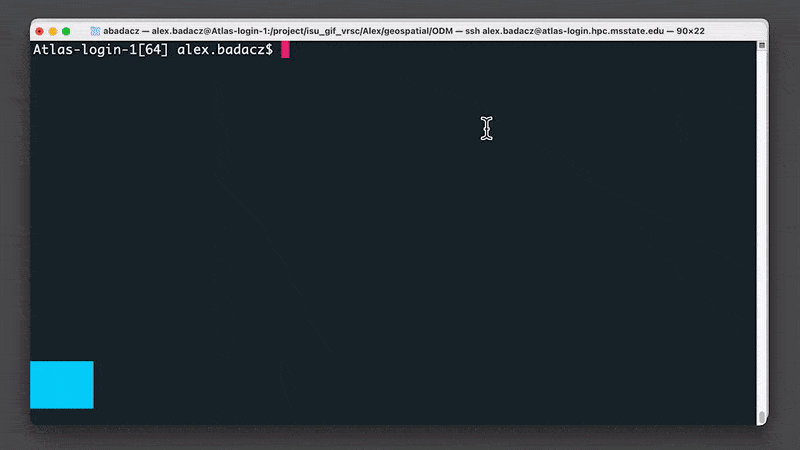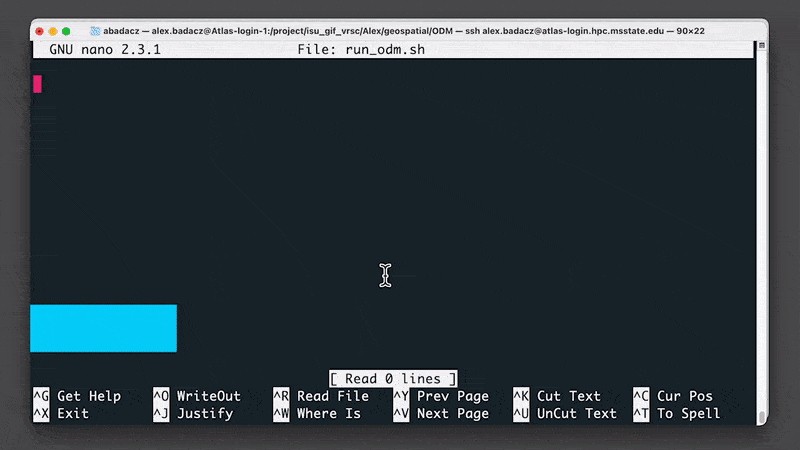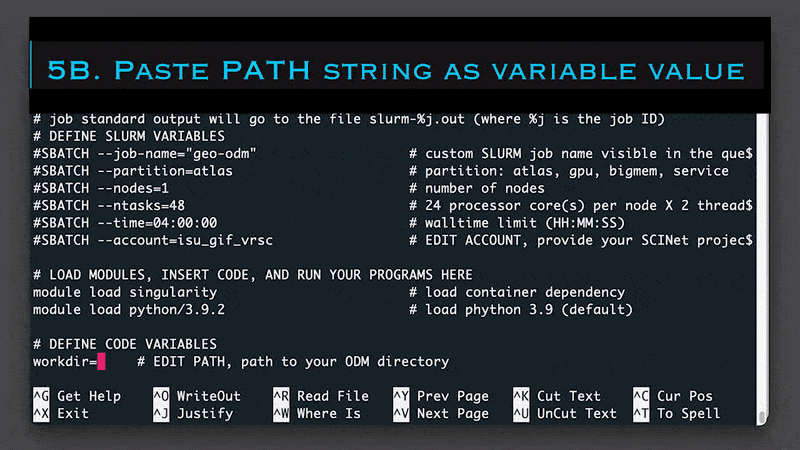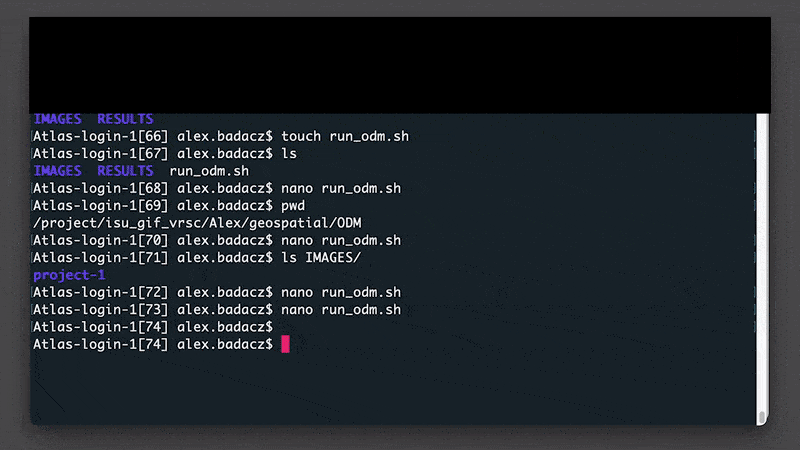
# DEFINE CODE VARIABLES
workdir=/project/<project_account>/.../ODM # EDIT PATH, path to your ODM directory; use `pwd` if the script is in ODM workdir
project=PROJECT-1 # EDIT PROJECT NAME, name of the directory with input JPG imagery
ODM=3.3.0
tag=$SLURM_JOB_ID # EDIT CUSTOM TAG, by default it is a SLURM job ID
#tag=`date +%Y%b%d-%T | tr ':' '.'` # alternative TAG, use date in format 2022Aug16-16.57.59 to make the name unique
images_dir=$workdir/IMAGES/$project # automatically generated path to input images when stored in ~/ODM/IMAGES; otherwise provide absolute path
output_dir=$workdir/RESULTS/$project-$tag # automatically generated path to project outputs
mkdir -p $output_dir/code/images # automatically generated images directory
ln -s $images_dir/* $output_dir/code/images/ # automatically linked input imagery
cp $BASH_SOURCE $output_dir/submit_odm.sh # automatically copied the SLURM script into the outputs directory (e.g., for future reuse or reference of used options)
odm=/reference/containers/opendronemap/$ODM/opendronemap-$ODM.sif # pre-configured odm image on Atlas
# DEFINE ODM COMMAND
apptainer run --writable-tmpfs $odm \
--feature-quality ultra --min-num-features 10000 --matcher-type flann \
--pc-quality ultra --pc-classify --pc-rectify --pc-las \
--mesh-octree-depth 12 \
--gcp $output_dir/code/images/gcp_list.txt \
--dsm --dtm --dem-resolution 1 --smrf-threshold 0.4 --smrf-window 24 \
--build-overviews \
--use-hybrid-bundle-adjustment --max-concurrency 72 \
--project-path $output_dir --ignore-gsd
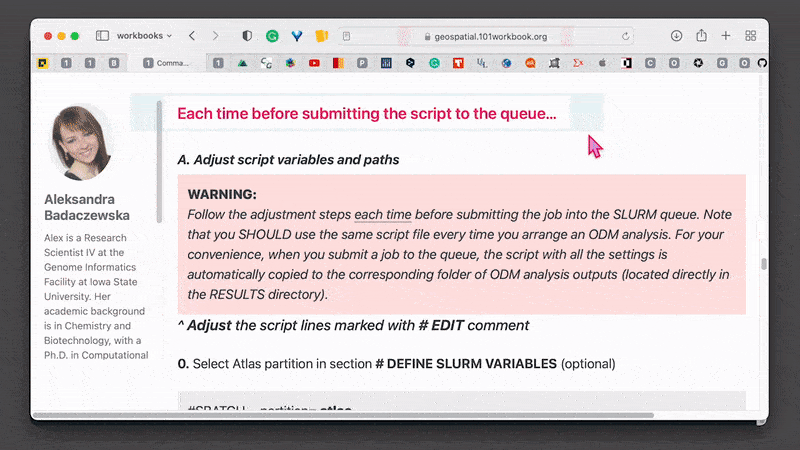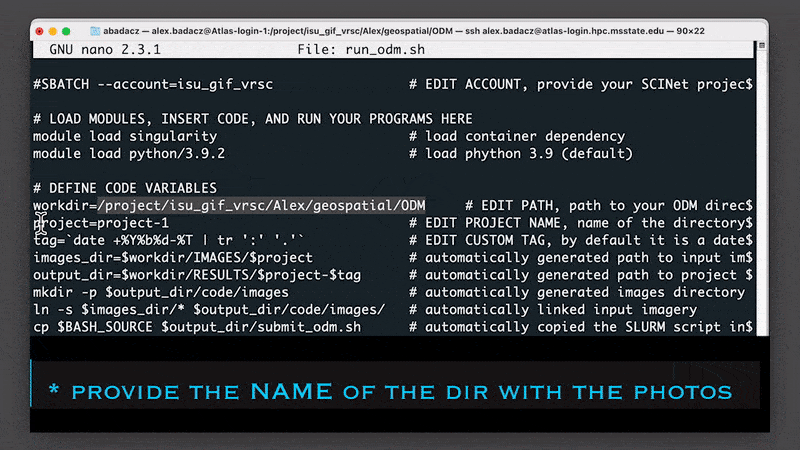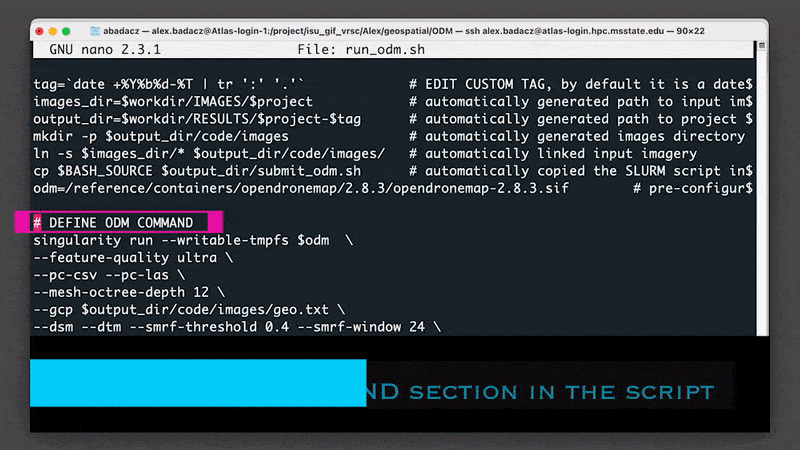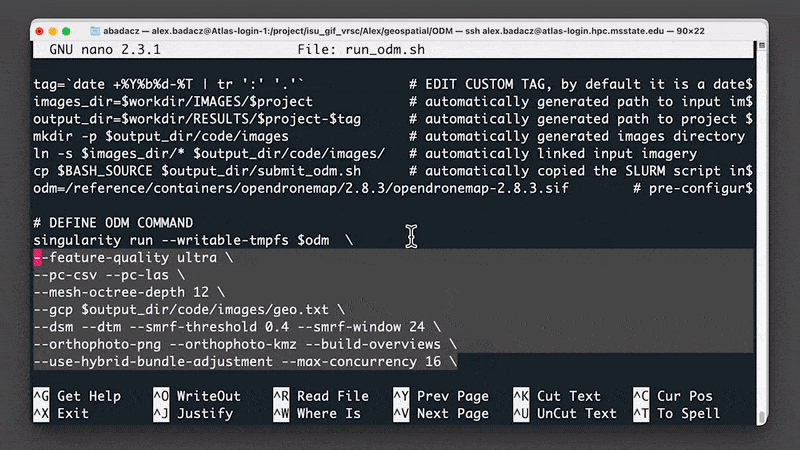
Each time before submitting the script to the queue…
A. Adjust script variables and paths
Follow the adjustment steps each time before submitting the job into the SLURM queue. Note that you SHOULD use the same script file every time you arrange an ODM analysis. For your convenience, when you submit a job to the queue, the script with all the settings is automatically copied to the corresponding folder of ODM analysis outputs (located directly in the RESULTS directory).
^ Adjust the script lines marked with # EDIT comment
0. Select Atlas partition in section # DEFINE SLURM VARIABLES (optional)
For most jobs, Atlas users should specify the atlas partition. The specification for all available Atlas partitions is provided in Atlas Documentation, in section Available Atlas Partitions.
1. Enter your SCINet project account in section # DEFINE SLURM VARIABLES (obligatory)
For example, I use isu_gif_vrsc account: #SBATCH --account=isu_gif_vrsc
2. Edit path to your ODM directory in section # DEFINE CODE VARIABLES (obligatory)
For example, I use the following path: workdir=/project/isu_gif_vrsc/Alex/geospatial/ODM
3. Edit name of the directory with input imagery in section # DEFINE CODE VARIABLES (obligatory)
IMPORTANT: This step determines which set of images will be used in the ODM analysis!
CASE 1: Note that the entered name should match the subdirectory existing directly in your ~/ODM/IMAGES/ where you store imagery for a particular analysis. Then you do NOT need to alter the images_dir variable (with the full path to the input photos) because it will be created automatically.
Keep images_dir default:
images_dir=$workdir/IMAGES/$project
CASE 2: Otherwise, give a customized (any) name for the project outputs but remember to provide the absolute path (of any location in the HPC file system) to the input photos in the images_dir variable.
Provide the absolute path to imagery:
images_dir=/aboslute/path/to/input/imagery/in/any/location
4. Edit tag variable to customize project outputs directory # DEFINE CODE VARIABLES (optional)
By default, the tag variable is tagging the name of the directory with the ODM analysis outputs by adding the $SLURM_JOB_ID when the job is submitted. Alternatively, it could be date and time (in the format: 2022Aug16-16:57:59). This prevents accidental overwriting of results for a project started from the same input images and makes the project name of each analysis unique.
# tag=`date +%Y%b%d-%T | tr ':' '.'`
You can overwrite the value of the tag variable in any way that will distinguish the analysis variant and make the name of the new folder unique.
Avoid overwriting the tag with manually typed words, and remember to always add an automatically generated randomization part in the variable to prevent overwriting the results in a previous project (for example, when you forget to update the tag).
If you want to assign a value to the tag variable as the result of a command, use backtick bash expansion around it,
tag=`command`.
B. Choose ODM options for analysis
The script template provided in this section has a default configuration of options available in the command-line ODM module. You may find that these settings are not optimal for your project. Follow the instructions in this section to learn more about the available ODM options and their possible values.
^ Adjust flags in the # DEFINE ODM COMMAND section in the script file
# DEFINE ODM COMMAND
singularity run --writable-tmpfs $odm \
--feature-quality ultra --min-num-features 10000 \ # photo alignment
--matcher-type flann
--pc-quality ultra --pc-classify --pc-rectify --pc-las \ # point cloud
--mesh-octree-depth 12 \ # meshing
--gcp $output_dir/code/images/gcp_list.txt \ # georeferencing
--dsm --dem-resolution 1 \ # 3D model: DSM
--dtm --smrf-threshold 0.4 --smrf-window 24 \ # 3D model: DTM
--build-overviews \ # orthophoto
--use-hybrid-bundle-adjustment --max-concurrency 16 \ # performance
--project-path $output_dir --ignore-gsd \ # inputs / outputs
--time # runtime info
The syntax of the first line launches via the singularity container the odm image, $odm. All further --X flags/arguments define the set of options used in photogrammetry analysis. For clarity and readability, a long command line has been broken into multiple lines using the special character, backslash \ . Thus, be careful when adding or removing options. Also, do NOT write any characters after backslash character (# comments are placed in this code block only for educational purposes). The order of the options entered does not matter but they have been grouped by their impact on various outputs. Finally, check that the code block with the ODM command does NOT contain blank lines between the options (this may be the case when you manually copy and paste into some text editors).
Note especially to update the path to the GCP file,
geo.txt (with the assignment of GCPs to images): --gcp $output_dir/code/images/geo.txt
If you do not have this file, completely remove this line from the script (instead of commenting with #). In that case, the EXIF metadata will be used.
You can find a complete list of all available options with a description in the official OpenDroneMap documentation: v2.8.8. Click on the selected headline in the list below to expand the corresponding section with options.
MANAGE WORKFLOW options
A. To end processing at selected stage use
--end-with option followed by the keyword for respective stage: 1. dataset | 6. odm_filterpoints | 10. odm_dem |
2. split | 7. odm_meshing | 11. odm_orthophoto |
3. merge | 8. mvs_texturing | 12. odm_report |
4. opensfm | 9. odm_georeferencing | 13. odm_postprocess [default] |
5. openmvs |
- To restart the selected stage only and stop use
--rerunoption followed by the keyword for respective stage (see list in section A). - To resume processing from selected stage to the end, use
--rerun-fromoption followed by the keyword for respective stage (see list in section A). - To permanently delete all previous results and rerun the processing pipeline use
--rerun-allflag.
--fast-orthophoto flag. It creates the orthophoto directly from the sparse reconstruction which saves the time needed to build a full 3D model. D. Skip individually other stages of the workflow:
- Skip generation of a full 3D model with
--skip-3dmodelflag in case you only need 2D results such as orthophotos and DEMs. Saves time! - Skip generation of the orthophoto with
--skip-orthophotoflag n case you only need 3D results or DEMs. Saves time! - Skip generation of PDF report with
--skip-reportflag in case you do not need it. Saves time!
PHOTO ALIGNMENT options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --feature-type | akaze, hahog, orb, sift | sift | algorithm for extracting keypoints and computing descriptors | |
| --min-num-features | integer | 10000 | minimum number of features to extract per image | More features ~ more matches between images. Improves reconstruction of areas with little overlap or insufficient features. More features slow down processing. |
| --feature-quality | ultra, high, medium, low, lowest | high | levels of feature extraction quality | Higher quality generates better features, but requires more memory and takes longer. |
| --resize-to | integer | 2048 | resizes images by the largest side for feature extraction purposes only | Set to -1 to disable or use --feature-quality instead. This does not affect the final orthophoto resolution quality and will not resize the original images. |
| --matcher-neighbors | positive integer | 0 | performs image matching with the nearest N images based on GPS exif data | Set to 0 to match by triangulation. |
| --matcher-type | bow, bruteforce, flann | flann | image matcher algorithm | FLANN is slower, but more stable. BOW is faster, but can sometimes miss valid matches. BRUTEFORCE is very slow but robust. |
SfM & DPC options
Structure from Motion (SfM) algorithm estimates camera positions in time (motions) and generates a 3D Dense Point Cloud (DPC) of the object from multi-view stereo (MVS) photogrammetry on the set of images.
| flag | values | default | description | notes |
|---|---|---|---|---|
| --sfm-algorithm | incremental, triangulation, planar | incremental | structure from motion algorithm (SFM) | For aerial datasets, if camera GPS positions and angles are available, triangulation can generate better results. For planar scenes captured at fixed altitude with nadir-only images, planar can be much faster. |
| --depthmap-resolution | positive float | 640 | controls the density of the point cloud by setting the resolution of the depthmap images | Higher values take longer to compute but produce denser point clouds. Overrides --pc-quality |
| --pc-quality | ultra, high, medium, low, lowest | medium | the level of point cloud quality | Higher quality generates better, denser point clouds, but requires more memory and takes longer (~4x/level). |
| --pc-geometric | off | improves the accuracy of the point cloud by computing geometrically consistent depthmaps | Increases processing time, but can improve results in urban scenes. | |
| --pc-classify | off | classify the point cloud outputs using a Simple Morphological Filter | You can control the behavior of this option by tweaking the --dem-* parameters. | |
| --pc-rectify | off | performs ground rectification on the point cloud | The wrongly classified ground points will be re-classified and gaps will be filled. Useful for generating DTMs. | |
| --pc-filter | positive float | 2.5 | filters the point cloud by removing points that deviate more than N standard deviations from the local mean | 0 - disables filtering |
| --pc-sample | positive float | 0.0 | filters the point cloud by keeping only a single point around a radius N [meters] | Useful to limit the output resolution of the point cloud and remove duplicate points. 0 - disables sampling |
| --pc-copc | off | exports the georeferenced point cloud | Cloud Optimized Point Cloud (COPC) format | |
| --pc-csv | off | exports the georeferenced point cloud | Entwine Point Tile (EPT) format | |
| --pc-ept | off | CSV format | exports the georeferenced point cloud | |
| --pc-las | off | exports the georeferenced point cloud | LAS format |
MESHING & TEXTURING options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --mesh-octree-depth | integer: 1 <= x <= 14 | 11 | octree depth used in the mesh reconstruction | It should be increased to 10-11 in urban areas to recreate better buildings / roofs. |
| --mesh-size | positive integer | 200000 | the maximum vertex count of the output mesh | It should be increased to 300000-600000 in urban areas to recreate better buildings / roofs. |
| --texturing-data-term | gmi, area | gmi | texturing feature | When texturing the 3D mesh, for each triangle, choose to prioritize images with sharp features (gmi) or those that cover the largest area (area). It should be set to area in forest landscape. |
| --texturing-keep-unseen-faces | off | keeps faces in the mesh that are not seen in any camera | ||
| --texturing-nadir-weight | positive integer | It should be increased to 29-32 in urban areas to reconstruct better edges of roofs. It should be decreased to 0-6 in grassy / flat areas. | ||
| --texturing-outlier-removal-type | none, gauss_clamping, gauss_damping | gauss_clamping | type of photometric outlier removal method | |
| --texturing-skip-global-seam-leveling | off | skips normalization of colors across all images | Useful when processing radiometric data. | |
| --texturing-skip-local-seam-leveling | off | skips the blending of colors near seams | ||
| --texturing-tone-mapping | none, gamma | none | turns on gamma tone mapping or none for no tone mapping |
GEOREFERENCING options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --force-gps | off | uses images’ GPS exif data for reconstruction, even if there are GCPs present | Useful if you have high precision GPS measurements.* If there are no GCPs, it does nothing. | |
| --gcp | PATH string | none | path to the file containing the ground control points used for georeferencing | |
| --use-exif | off | EXIF-based georeferencing | Use this tag if you have a GCP File but want to use the EXIF information for georeferencing instead. | |
| --geo | PATH string | none | path to the image geolocation file containing the camera center coordinates used for georeferencing | Note that omega/phi/kappa are currently not supported (you can set them to 0). |
| --gps-accuracy | positive float | 10 | value in meters for the GPS Dilution of Precision (DOP) information for all images | If you use high precision GPS (RTK), this value will be set automatically. You can manually set it in case the reconstruction fails. Lowering the value can help control bowling-effects over large areas. |
DSM - Digital Surface Model options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --dsm | off | builds DSM (ground + objects) using a progressive morphological filter | Use ---dem* parameters for finer tuning. | |
| --dem-resolution | float | 5.0 | DSM/DTM resolution in cm / pixel | The value is capped to 2x the ground sampling distance (GSD) estimate. ^ use –-ignore-gsd to remove the cap |
| --dem-decimation | positive integer | 1 | decimates the points before generating the DEM 1 is no decimation (full quality) 100 decimates ~99% of the points | Useful for speeding up generation of DEM results in very large datasets. |
| --dem-euclidean-map | off | computes an euclidean raster map for each DEM | Useful to isolate the areas that have been filled. | |
| --dem-gapfill-steps | positive integer | 3 | number of steps used to fill areas with gaps 0 disables gap filling | see details in the docs For urban scenes increasing this value to 4-5 can help produce better interpolation results in the areas that are left empty by the SMRF filter. |
DTM - Digital Terrain Model options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --dtm | off | builds DTM (ground only) using a simple morphological filter | Use --dem* and --smrf* parameters for finer tuning. | |
| --smrf-threshold | positive float | 0.5 | Simple Morphological Filter elevation threshold parameter [meters]; elevation threshold | Set this parameter to the minimum height (in meters) that you expect non-ground objects to be. This option has the biggest impact on results! |
| --smrf-window | positive float > 10 | 18.0 | Simple Morphological Filter window radius parameter [meters] | It corresponds to the size of the largest feature (building, trees, etc.) to be removed. Should be set to a value higher than 10. |
| --smrf-slope | positive float in range 0.1 - 1.2 | 0.15 | Simple Morphological Filter slope parameter; a measure of “slope tolerance” | Increase this parameter for terrains with lots of height variation. |
| --smrf-scalar | positive float | 1.25 | Simple Morphological Filter elevation scalar parameter | Increase this parameter for terrains with lots of height variation. |
ORTHOPHOTO options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --orthophoto-resolution | float > 0.0 | 5.0 | orthophoto resolution in cm / pixel | |
| --orthophoto-compression | JPEG, LZW, LZMA, DEFLATE, PACKBITS, NONE | DEFLATE | compression to use for orthophotos | |
| --orthophoto-cutline | off | generates a polygon around the cropping area that cuts the orthophoto around the edges of features | The polygon can be useful for stitching seamless mosaics with multiple overlapping orthophotos. | |
| --orthophoto-png | off | generates rendering of the orthophoto | PNG format | |
| --orthophoto-kmz | off | generates rendering of the orthophoto | Google Earth (KMZ) format | |
| --orthophoto-no-tiled | off | generates striped GeoTIFF | ||
| --build-overviews | off | builds orthophoto overviews | Useful for faster display in programs such as QGIS. | |
| --use-3dmesh | off | uses a full 3D mesh to compute the orthophoto instead of a 2.5D mesh | This option is a bit faster and provides similar results in planar areas. By default, the 2.5D mesh is used to generate the orthophoto (which tends to work better than the full 3D mesh). |
GENERAL QUALITY OPTIMIZTION options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --auto-boundary | off | automatically set a boundary using camera shot locations to limit the area of the reconstruction | Useful to remove far away background artifacts (sky, background landscapes, etc.). | |
| --boundary | JSON file | none | GeoJSON polygon limiting the area of the reconstruction | Can be specified either as path to a GeoJSON file or as a JSON string representing the contents of a GeoJSON file. |
| --camera-lens | auto, perspective, brown, fisheye, spherical, dual, equirectangular | auto | camera projection type | Manually setting a value can help improve geometric undistortion. |
| --cameras | JSON file | none | camera parameters computed from another dataset | Use params from text file instead of calculating them. Can be specified either as path to a cameras.json file or as a JSON string representing the contents of a cameras.json file. |
| --use-fixed-camera-params | off | turns off camera parameter optimization during bundle adjustment | This can be sometimes useful for improving results that exhibit doming/bowling or when images are taken with a rolling shutter camera. | |
| --cog | off | creates cloud-optimized GeoTIFFs instead of normal GeoTIFFs |
PERFORMANCE OPTIMIZATION options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --use-hybrid-bundle-adjustment | off | runs local bundle adjustment for every image added to the reconstruction and a global adjustment every 100 images | Speeds up reconstruction for very large datasets. | |
| --max-concurrency | positive integer | 4 | maximum number of processes to use in various processes | Peak memory requirement is ~1GB per thread and 2 megapixel image resolution. |
| --no-gpu | off | does not use GPU acceleration, even if it’s available | ||
| --optimize-disk-space | off | deletes heavy intermediate files to optimize disk space usage | This disables restarting the pipeline from an intermediate stage, but allows the analysis on machines that don’t have sufficient disk space available. |
INPUT / OUTPUT MANAGEMENT options
| flag | values | default | description | notes |
|---|---|---|---|---|
| --project-path | PATH string | none | path to the project folder | Your project folder should contain subfolders for each dataset. Each dataset should have an images folder. |
| --name | NAME string | code | name of dataset | That is the ODM-required subfolder within project folder. |
| --ignore-gsd | off | ignores Ground Sampling Distance (GSD) | GSD caps the maximum resolution of image outputs and resizes images, resulting in faster processing and lower memory usage. Since GSD is an estimate, sometimes ignoring it can result in slightly better image output quality. | |
| --crop | positive float | 3 | crop image outputs by creating a smooth buffer around the dataset boundaries, shrunk by N meters | Use 0 to disable cropping. |
| -copy-to | PATH string | none | copies output results to this folder after processing |
See description of other options directly in the OpenDroneMap documentation:
- general usage: help, debug,
- large datasets [ODM docs]: split, split-image-groups, split-overlap,
- multispectral datasets [ODM docs]: primary-band, radiometric-calibration, skip-band-alignment,
- rolling-shutter camera: rolling-shutter, rolling-shutter-readout
Submit ODM job into the SLURM queue
The SLURM is a workload manager available on the Atlas cluster. It is a simple Linux utility for resource management and computing task scheduling. In simple terms, you HAVE to use it every time you want to outsource some computation on HPC infrastructure. To learn more about SLURM take a look at the tutorial SLURM: Basics of Workload Manager available in the DataScience Workbook.
If you are working on an HPC infrastructure that uses the PBS workload manager, take a look at the tutorial PBS: Portable Batch System to learn more about the command that sends a task to the queue and the script configuration.
[source: DataScience Workbook]
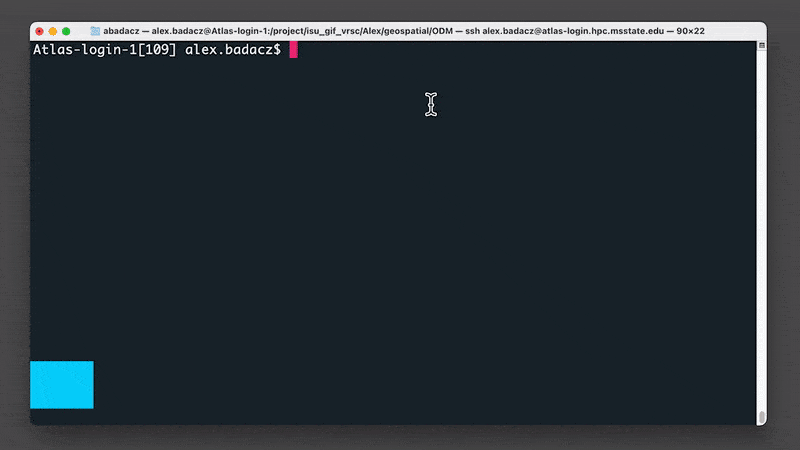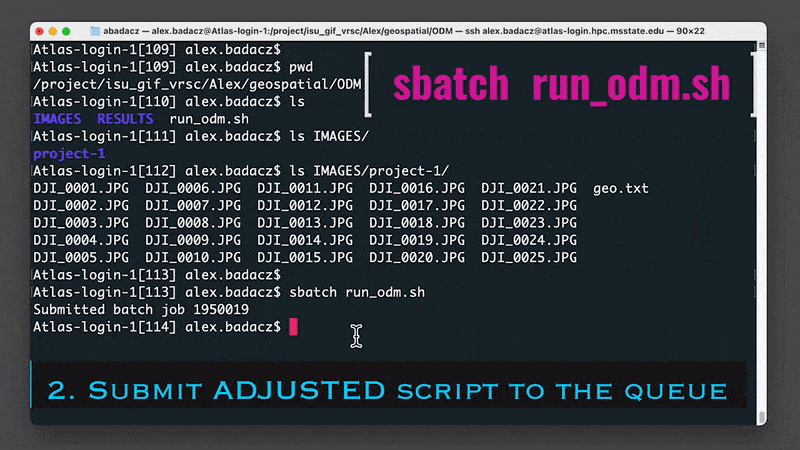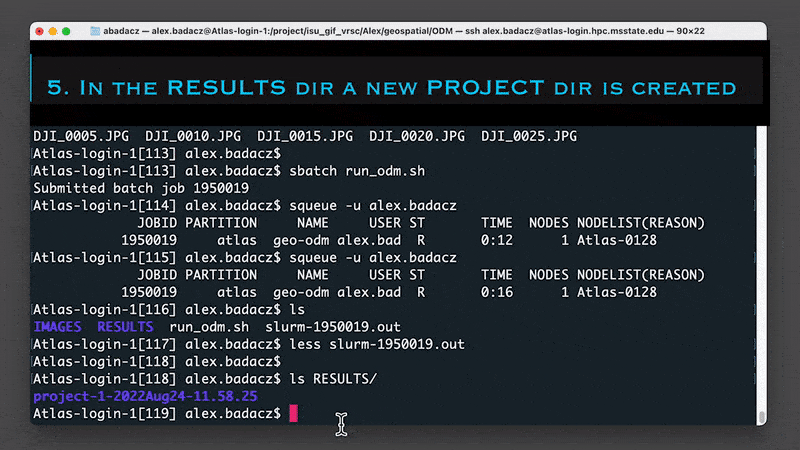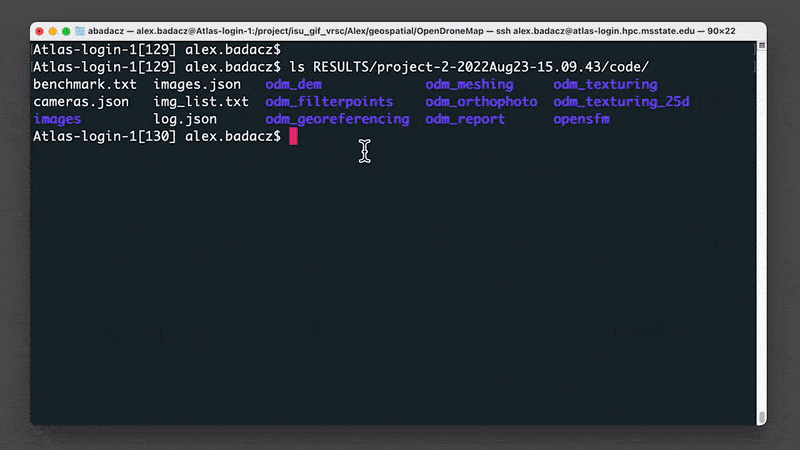
Use the sbatch SLURM command to submit the computing job into the queue:
sbatch run_odm.sh
Tasks submitted into the queue are sent to powerful compute nodes, while all the commands you write in the terminal right after logging in are executed on the capacity-limited login node.
Never perform an aggravating computation on a logging node.
A. If you want to optimize some computationally demanding procedure and need a live preview for debugging, start an interactive session on the compute node.
B. If you want to migrate a large amount of data use transfer node: @atlas-dtn.hpc.msstate.edu.
Use the squeue SLURM command to check the status of the job in the queue:
squeue -u user.name # e.g., squeue -u alex.badacz

Access ODM analysis results
Use the ls command to display contents of the directory with outputs:
ls /project/<scinet_account>/<user-specific-path>/ODM/RESULTS/<project-name>/code
e.g., ls /project/isu_gif_vrsc/Alex/geospatial/ODM/RESULTS/project-1-2022Aug24/code/

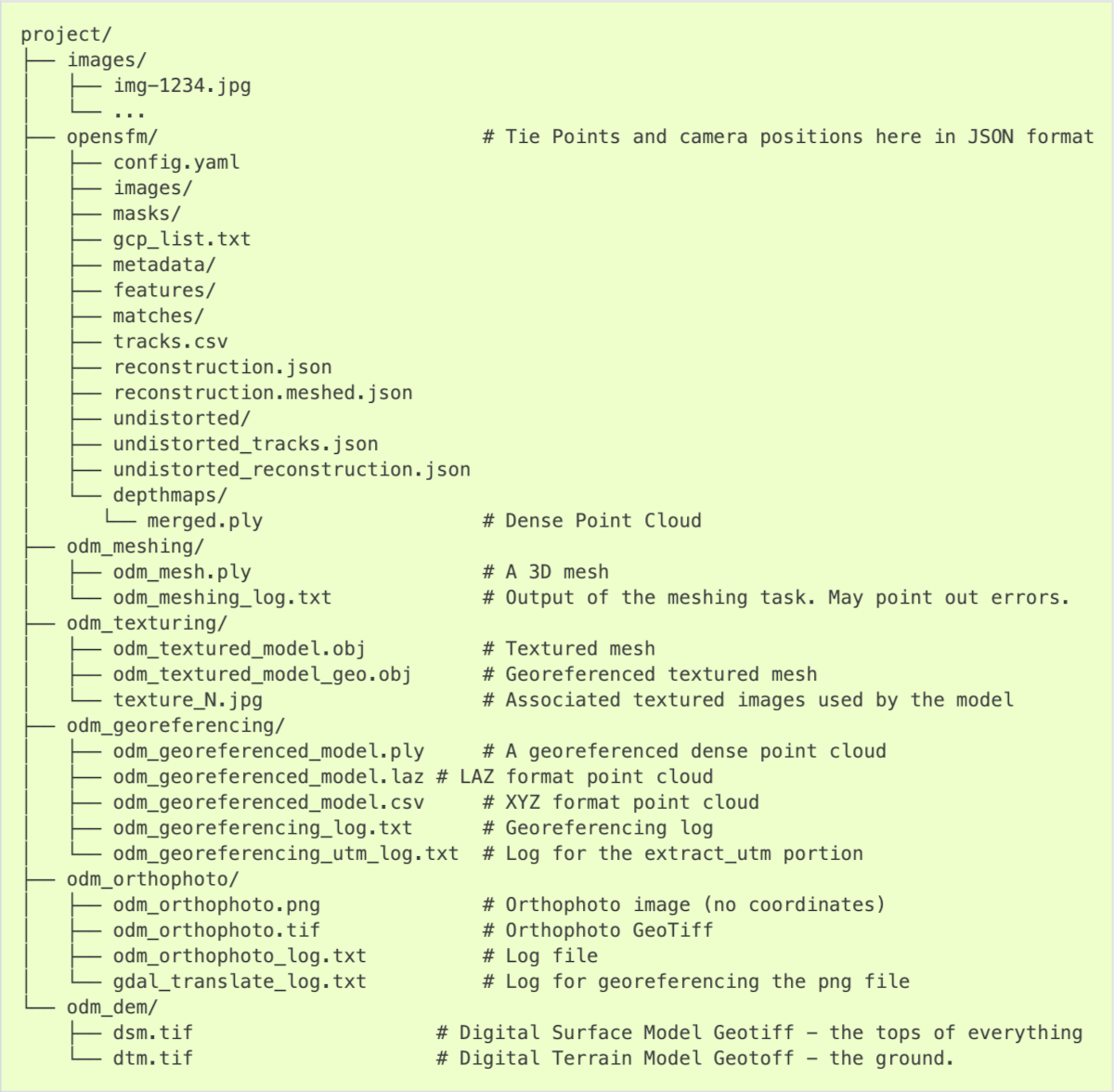
The figure below shows the file structure of all outputs generated by the ODM command-line module. The original screenshot comes from the official OpenDroneMap (v2.8.7) Documentation.
Get ODM on local machine
Download the ODM module
A. Download docker image using singularity
^ suggested for usage on computing machines where the singularity is available
module load singularity
singularity pull --disable-cache docker://opendronemap/odm:latest
Do it only once (!) when the first time you configure your work with the command-line ODM module. Once created, the singularity image of an ODM tool can be used any number of times.
Executing the code in the command line should create a new file named odm_latest.sif. This is an image of an ODM tool whose configuration ensures that it can be used efficiently on an HPC cluster. You can check the presence of the created file using the ls command, which will display the contents of the current directory.
B. Download docker image using Docker
^ suggested for usage on computing machines where the Docker can be installed
^ requires prior Docker installation, follow instructions for your OS at docs.docker.com
# Windows
docker run -ti --rm -v c:/Users/youruser/datasets:/datasets opendronemap/odm --project-path /datasets project
# Mac or Linux
docker run -ti --rm -v /home/youruser/datasets:/datasets opendronemap/odm --project-path /datasets project
C. ODM at GitHub: https://github.com/OpenDroneMap/OpenDroneMap/
git clone https://github.com/OpenDroneMap/ODM.git
D. Download zipped source code: https://github.com/OpenDroneMap/OpenDroneMap/archive/master.zip
get https://github.com/OpenDroneMap/OpenDroneMap/archive/master.zip